Google: DORA Metrics and Capabilities for Elite Performance DevOps
Google research identifies the metrics and capabilities of elite performing DevOps teams.
 Google publishes the Accelerate State of DevOps report (2023 version).
Google publishes the Accelerate State of DevOps report (2023 version).
Over the past seven years, more than 32,000 professionals worldwide have taken part, making it the largest and longest-running research of its kind.
They identify four key metrics of high performance delivery, which can be considered in terms of two core objectives: Throughput and stability – How fast reliable code can be developed.
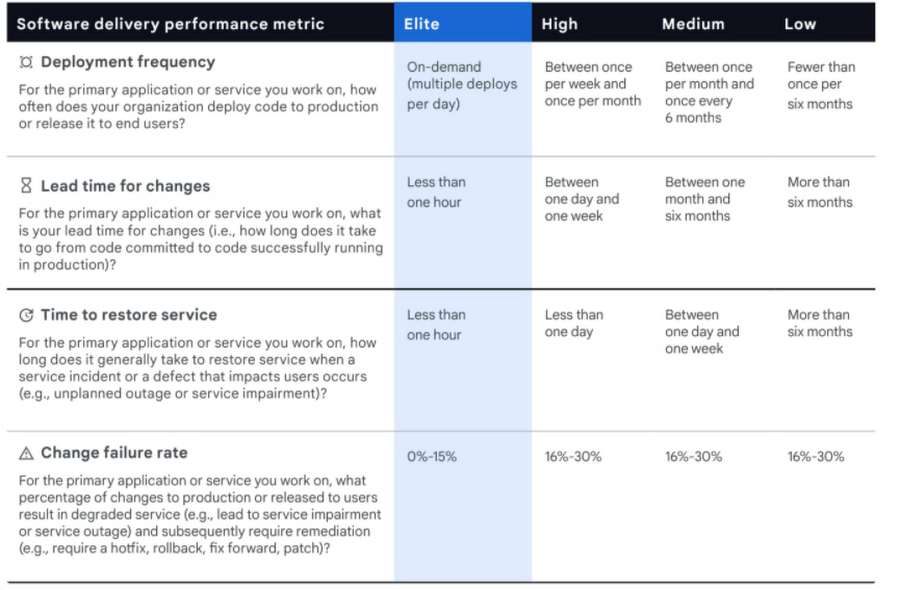
The report identified four metrics to classify teams as elite, high, medium or low performers based on their software delivery:
- Deployment frequency.
- Lead time for changes.
- Mean-time-to-restore.
- Change fail rate.
These are measured through i) lead time of code changes (time from code commit to release in production) and deployment frequency, and ii) time to restore a service after an incident and change failure rate.
Elite Performance
The report identified four metrics to classify teams as elite, high, medium or low performers based on their software delivery.
Elite performers have control over their environment such that only 0-15% of their new changes cause failures, versus 16-30% for the others.
They also deploy new releases much more frequently and can do so in less than an hour. The metrics we described above provide the measurement and management framework needed to improve along with these scales and mature from Low to Elite performance levels.
High Performance Capabilities
They also identify the following technical practices as key to achieving this high performance DevOps:
- Loosely coupled architecture – Teams that can scale, fail, test and deploy independently of one another. They work at their own pace and in smaller batches, accrue less technical debt and recover faster from failure.
- Continuous integration and testing – Elite performers are 3.7 times more likely to leverage continuous testing. By incorporating early and frequent testing throughout the delivery process, with testers working alongside developers throughout, teams can iterate and make changes to their product, service, or application more quickly.
- Trunk-based development – Developers work in small batches and merge their work into a shared trunk frequently. Elite performers who meet their reliability targets are 2.3 times more likely to use trunk-based development.
- Deployment automation – When you move software from testing to production in an automated way, you decrease lead time by enabling faster and more efficient deployments. You also reduce the likelihood of deployment errors, which are more common in manual deployments.
- Database change management – Tracking changes through version control is a crucial part of writing and maintaining code, and for managing databases. Elite performers who meet their reliability targets
are 3.4 times more likely to exercise database change management compared to their low-performing counterparts. - Monitoring and observability – Elite performers who successfully meet their reliability targets are 4.1 times more likely to have solutions that incorporate observability into overall system health. Observability practices give your teams a better understanding of your systems, which decreases the time it takes to identify and troubleshoot issues
Adoption of continuous practices ranges across the scale, with almost half saying they have been able to implement continuous integration, but it then drops away as they assess continuous delivery and then deployment maturity. Only a third of respondents said they deploy new code at least once per week, and almost half still deploy less than once per month. The number of teams that deploy new code daily or multiple times a day (15%) is roughly equivalent to those that deploy code on a quarterly basis (16%).
The most widely used DevOps tools are GitHub, Jenkins, GitLab, Azure Pipelines and Bitbucket. The most widely automated tests are user interface (UI)/functional and unit tests, followed by regression and integration testing, using tools including Selenium, Cypress, Postman, SoapUI and homegrown tools.




